So I test drove a Model 3, and I have some thoughts.
Backstory
I feel like everyone has a story about when they got interested in Tesla. For me it was summer of 2012 just before the official release of the Model S. I was at Coit Tower in San Francisco and on the way back to the parking lot when I noticed a black Model S. I don’t remember how I’d heard about Tesla, but when I saw the car that day I remember doing a double take after realizing it was a Model S. Seeing it was so unexpected, but the thing was the coolest gadget: an all electric car with a giant touch screen. From that moment on, I wanted one. The only problem, the price tag was prohibitively expensive. (I settled for buying a few shares of stock in the company, yet not enough to afford a car now)
So six years later, the Model 3 is rolling out to the general public with the allure of a $35,000 Tesla. Still all electric with a giant touch screen, plus crazy features like autopilot no one would have imagined to be possible back in 2012.
Before the test drive, I had never been in a Tesla on the road let alone driven one. I was purposely avoiding the car knowing I would want one even more after I went for a test drive. But TL;DR, surprisingly that wasn’t the case. I’ve spent so many years thinking about the economics of owning a Tesla while listening to others talk about what the cars are like to drive and own. When I got to actually drive the Model 3, I already had my expectations and mind set on not buying one. I tend to be pretty frugal, and try to be rational about buying things that I really need instead of overspending on cool things that are just for fun (looking at you DJI Mavic…), so I knew going in that the car would be a blast, but an unnecessary purchase for me at this time. Maybe a few years down the road, when my current car starts to show its age and EV costs have been subsidized further by increased production, I’ll finally be ready to get a Tesla. For now, driving a Model 3 was just a fun thing do on one hazy Sunday morning.
Test Drive Experience
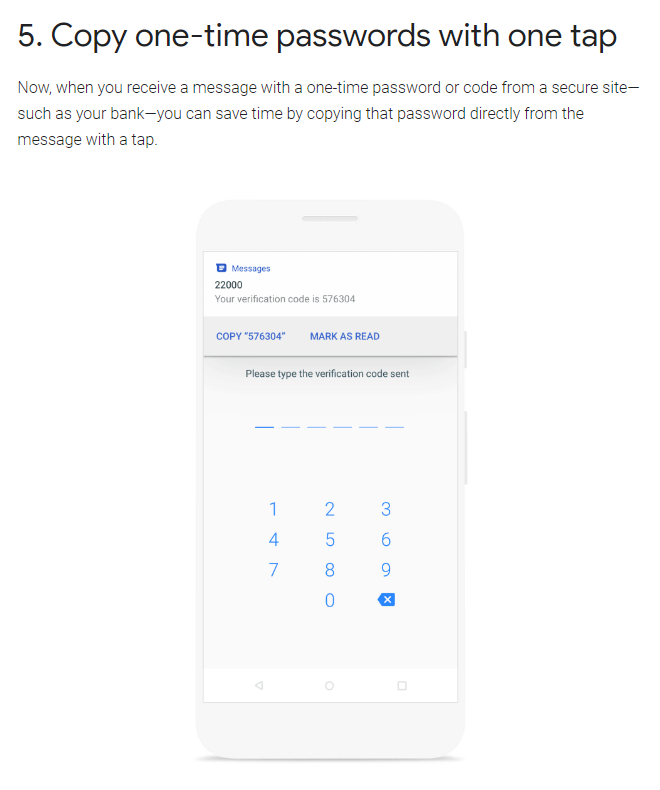
I signed up to test drive the $55,000 model with long range battery and dual motor. I specifically did not want to try the upgraded performance model because it was out of my price range (even more so than the mid tier model), and I didn’t want my first impression to be with the highest end model. The test drive started out with a warning that someone had backed the mid tier model into a wall, so we’d be driving the high end performance model. (Um, how does that happen? Aren’t all the cameras and sensors supposed to be able to prevent such a thing from happening? My question went unanswered and we hopped into the car.)
I immediately realized there would be a steep learning curve to understanding the controls. The first thing I usually do when setting out to drive a new car is adjust the mirrors (as I try to be a good driver), but there is no dial on the driver door panel. It turns out you have to tap the “car” button in the bottom left of the screen to bring up the controls menu, but without the sales associate to point me to the menu, this would have been a complicated task of searching through menu options.
Settings & controls
I could see myself sitting in the car for 30 minutes to an hour just figuring out what it can do and customizing it all to my liking. A Tesla feels like a gadget and tries to bring the simplicity of a smartphone design to a car. It works to an extent, and definitely would take time to get used to. When I found myself wondering if there was a setting to adjust the rearview mirror, or if I could just reach up and do it manually, I knew I was a bit overwhelmed by all the changes to the controls. Luckily, the controls for seat position adjustment are still on the side of the seat, so some of your muscle memory may still transfer over. It’s just hard to tell when that’s the case.
Steering
I drove the 3 out of the parking lot, the first thing I noticed was how heavy the car felt and the weight of the steering. The car feels strong, big, and solid. Turning the wheel takes effort, but not an absurd amount, just enough to give you firm sense of control. I wonder now if this is another setting Tesla programs into the car. Could there be a “light” steering mode that reduces the tension in the wheel? I don’t know why they would do such a thing, but it seems possible.
Turn signals are confusing.
Because the controls are reduced to a wheel, two stalks, and a screen, many of the controls act differently than a normal car. The turn signal for example always returns to the center, which is confusing because for all the car’s I’ve ever drive, a turn signal in the center position means its off. Pushing to the up or down position will turn right or left. I learned there is a short and a long press to the turn signal stalk, but I didn’t figure out exactly how it worked. All I know is that as long as you ignore the fact the stalk always returns to the middle position, you can signal for starting and completing turns by pushing up or down the same way you would on any other car. The 3 is even smart enough to recognize when you’ve completed a turn, but in some cases when I put the signal on too early, the car decided to turn the signal off before I even made it to the turn.
Blast off
The Model 3 goes 0 to 40 goes by in a flash and you don’t realize how fast you’re going because it happened so quickly. Just to reiterate, I was trying the Performance upgrade, so the pick up probably won’t be as powerful on lower models, but the immediate feedback and roller coaster feel, should be transferrable. There was a car ahead as I merged onto the highway, so instead rocketing by at the last minute, leaving the car in of in a cloud of dust, I decided to play it safe and drive like a normal person.
Enhanced Autopilot, lane keeping, and distance control
The vision system gives the Model 3 a super cruise control mode. In addition to maintaining speed, the car will help you stay in your lane if you start to drift, and keep the same distance between the car in front of you whether the car speeds up or slams on its brakes. Tesla notes, “Enhanced Autopilot includes additional driver assistance features. Every driver is responsible for remaining alert and active when using Autopilot, and must be prepared to take action at any time.”
Full Self-Driving Capability with hands nearby and automatic lane changing
This was just nutty. Pull down twice on the right stalk to engage full self driving mode, and you can take your hands off the wheel as the car drives itself. The same lane keeping and distance controls apply to the full self-driving mode as they do with auto pilot, but now they are the sole means of maneuvering the car down the freeway. I (eerily) quickly grew accustomed to the car driving me as we stayed in the same lane, but the craziest part is changing lanes. Simply pull down or push up the left stalk to let the car know you want to turn left or right. The car determines the lane is clear and moves on over. It’s wild. We’re not quite at the point of removing the steering wheel, but this still feels like the future. Again, Tesla includes a disclaimer, “This functionality is dependent upon extensive software validation and regulatory approval. It is not possible to know exactly when it will be available, as this is highly dependent on local regulatory approval, which may vary widely by jurisdiction.”
Other Tesla and EV specific things
Hold mode puts keeps the car in place when you push in the break all the way at a stop. Creep had to be programmed in because EVs do not inch forward in the same way a gas engine does while idling. Unlike a cell phone or laptop which has charge limiters for batteries, you have to set the max charge for a Tesla (~90% while city driving, and 100% for long road trips). Avoiding a full charge helps keeps the battery in good condition for longer.
Features & Pricing
The whole point of the test drive is to make a decision about buying the car, right? So what configuration do you want to get? Most of us bought into the allure of a $35,000 Tesla when the Model 3 was announced two years ago, but we still aren’t quite there yet.
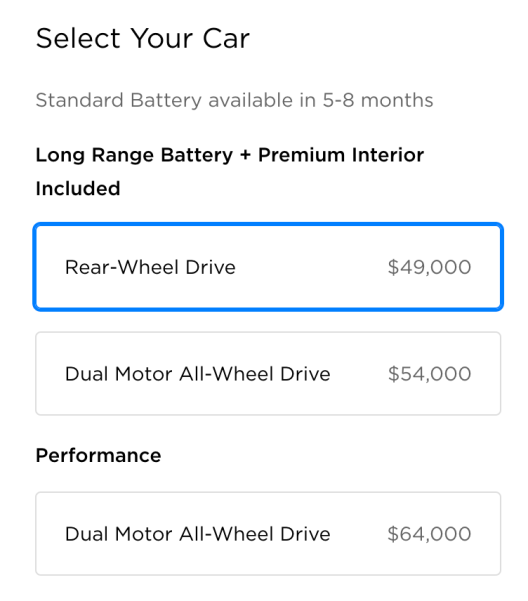
This is all brilliant marketing by Tesla to lure you in with the $35,000 option, anchoring your first impression of the car to a lower price, while only selling configurations that can cost upwards of double the base price for the next 5 to 8 months (as of late August 2018).
So the $35,000 (or $27,500 when considering the $7500 credit) you were expecting to pay immediately goes up by $14,000 for the Long Range model with rear wheel drive. Want Long range and Dual motor? That’s another $5000 or $19,000 over the price of the base model. You could buy one Model 3 or three cars for $54,000, and that doesn’t even include the “cool” Tesla features like Autopilot or Full Self-Driving mode add-ons (for an additional $8000). At the high end, the Performance model can cost up to $80,500. How is that affordable?
A formative view for my understanding of the value of the Model 3 came from Mr. Money Mustache. He thinks about buying a Model 3 while considering cost-per-use in relation to the base $35,000 model and upgrade options.
“I’m thinking of springing for the $9000 long-range battery in my upcoming Tesla Model 3 order” – this one strikes straight at my own heart, because I crave a long range Model 3 myself. But even for a serious roadtripper, this works out to $125 per hour of charging time that you manage to avoid. Aren’t you willing to take a few minutes occasionally to walk around and admire your beautiful car if you get paid $125 per hour after tax for it? If you are, standard range will do.
Calculations:
Tesla Battery Upgrade: The only time you use the longer range is on roadtrips over 230 miles. If you do a 600-mile trip once every month, you have to make two extra 30-minute charging stops per month. Figure the $9000 battery costs you about $1500 in extra capital cost and depreciation per year, or $125 per month. However, if you are a Tesla fan like me and you want the company to make more profit to continue their mission, you may still opt for the extra options since you have nothing better to do with that money anyway.
All wheel drive car: if the car costs $5000 more up-front plus an extra $200 per year in fuel and maintenance, you could estimate it as about $500 per year more expensive to own. Then, how many times do you truly get stuck in a front-wheel drive car with really good dedicated snow tires on winter rims? (because snow tires always come before buying AWD!)
via MMM The Twenty Dollar Swim
If you are trying to decide to buy now or wait, a commenter brings up a valid point: “Getting the larger battery gets you the full $7500 tax credit, getting the smaller battery likely doesn’t.” This is because Tesla’s US federal tax credit will expire at the end of 2018. The lucrative $7500 will only apply to vehicles delivered (not ordered) before December 31, 2018. Afterwards the credit will decrease by half and expire at the end of 2019.
Let’s consider how this pricing scheme came to be because it all seems a bit out of proportion.
Upgrade Perception
Before we get into Model 3 pricing, first think about what you get by upgrading from public transit to a car (of any kind), then move to what you get for the base line Model 3 and above.
Owning a car is a luxury allowing you to move around on your own time and optimize the routes you drive. You don’t have to adhere to bus schedules, try to find rides with people, or spend time going out of your way. A car takes a psychological load off your mind that gives you the freedom to engross yourself in your work without ever worrying about rushing to make a bus that leaves in the next 5 minutes. In many places a car is not a necessity, but it can be a quality of life improvement.
On the other hand, not owning a car has its upsides. For one, there is a significant cost savings when factoring paying for a car, insurance, gas, tolls, parking, and maintenance. It’s not unreasonable for owning a car to cost upwards of $10,000 a year (with a rough estimate of $400 a month for loan, $250 for parking and tolls, $150 for insurance, $150 for gas). Plus, you can get a lot done on the bus/train/taxi when you aren’t the one who must be engaged behind the wheel.
Ok, so for any car you decide to go with (or not) you’ll have to weigh these pros and cons. Driving a Tesla does not magically change the dynamics of owning a car any more than driving a Subaru does (yet. We’ll have to wait for advancements in autopilot and changes to regulations). If owning a car is a luxury, owning a Tesla is an opulence.
Let’s say you’ve decided against the advice of the Millionaire Next Door and are in the market for a new car under $50,000. What would persuade you to upgrade from a $35,000 Model 3 to a more premium package?
The Model 3 is a curious case of behavioral economics. It is more common for car brands to price multiple models across a $35,000 to $80,500 price range with visibly distinct prestige of owning a higher end car. Just look at the BMW line-up, they (logically) use a numbering scheme that increases with perceived prestige. For the Model 3, the body looks the same for all price configurations of the car, the only distinguishing factor is the tires (and this little badge on the back). Is it any wonder why the upgraded wheels cost an arm and a leg? It’s how you show you got the nicer car. Tesla is not the only company to do this. Apple is a constant offender, tweaking iPhone design to show make newer models easily recognizable, and adding a big red dot to their latest and greatest watch.
This makes business sense. For a company to make the most from its high end customers in order to subsidize lower end products is nothing new either. Apple also does this with the iPhone and Mac in regard to spec upgrades. The build quality, apps, OS, customer support, and general Apple ecosystem are all the same no matter of the type of iPhone or Mac you decide to purchase.
The majority of Apple’s margins come from upgrades that cost them a tens of dollars that they sell to you for hundreds (or thousands).
There’s nothing inherently wrong with this. It’s how Apple continues growing even with a trillion dollar valuation.
when you raise prices and a segment of your customer base will only buy the best, you can achieve higher average selling prices — over $100 higher year-over-year ($796 versus $694) — which means higher revenue.
Charging its best customers more for iPhones wasn’t the only reason Apple’s revenue was higher, though: remember that Apple is making more off of every customer over time via Services. And there is one more piece: Apple is selling its best customers more and more devices.
Apple’s Middle Age via Stratechery
And Tesla is doing the same thing. The baseline $35,000 Model 3 gets you the same build quality, software upgrades, autopilot hardware, customer service, brand prestige, and roller coaster acceleration. Higher margin cars will subsidize the more affordable models at larger scale, they even called it out as their master plan ten years ago:
- Build sports car
- Use that money to build an affordable car
- Use that money to build an even more affordable car
- While doing above, also provide zero emission electric power generation options
Tesla’s Master Plan
However, making business sense does not absolve companies of the psychological manipulation they employ with these pricing strategies. By singling out the one feature you get for a disproportionately large amount of money over the cost of the base product, companies frame upgrades to make you forget about all you get when you initially decide to opt for their product without the extra bells and whistles. Just look at the similarities across the iPad lineup. If Apple only pointed out the commonalities, people would question upgrading, so Apple makes the differentiators big, bold, and right at the top.
Whether you just have money to spend and only settle for the top of line, or have been saving for years only to wait a few months longer, consider the return on investment when spec’ing out a Model 3 (and anything else you buy). Maybe you ski every day and need all wheel drive, or live so far away from charging station that the larger battery is a must, but if that’s not the case for you, is the baseline good enough? After all, you’re still getting a Tesla.
So buy now or wait?
This totally depends on your budget. For me, I’ve had my current car for three years, and plan to keep it for at least 10. If you need a new car right now, and are looking at a Tesla, maybe this helps to think more rationally about the purchase. A used Chevy Volt is a decent alternative that checks many of the same boxes as a Tesla.
And if you’re set on a Tesla, just consider if driving down the highway knowing you’re safe with your hands off the wheel is worth $8,000, It is fun to be an early adopter, but why not let others subsidize your cost a bit? Are you going to buy one of these?

:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/9276345/jbareham_170916_2000_0088.jpg)
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/9597629/jbareham_171101_2099_A_0104.jpg)